
Quick links
- Background
- Searchable snapshots in cold and frozen tiers
- Manual mounting with a fully mounted index
- Manual mounting with a partially mounted index
- The differences between fully and partially mounted indices
- Conclusion
Background
Searchable snapshots were introduced in Elasticsearch 7.10 to solve a common problem: how to explore data that is no longer located in the cluster but rather in an object repository, like AWS S3.
Before searchable snapshots were available, to explore that kind of data you would have had to do a snapshot/restore operation manually, then run the search, and then delete the index to release the disk space. Searchable snapshots introduced the concept of automatic “mounting” of a snapshot, which means making it searchable.
Searchable snapshots can be controlled with Index Lifecycle Management Policies or manually mounted.
In this article, we explore the latter and explain the differences between a “fully mounted” and a “partially mounted” index.
To understand that difference, it is first necessary to look at how searchable snapshots work in both cold and frozen tiers.
However, before turning to that, it is important to note that an Elastic Enterprise license is required to use the searchable snapshot feature.
Searchable snapshots in cold and frozen tiers
Cold and frozen tiers take advantage of the new searchable snapshots feature in different ways:
- Cold tiers: Store replicas in a data repository instead of the node’s local storage. If the local data gets corrupted, the node will fetch the data from the repository. When a full copy of an index is loaded from the repository, it is called a “fully mounted index”.
- Frozen tiers: Store part of the data (the pieces that are searched most frequently) in the local cache. The rest of the data lives in the data repository. If you run a search and part of the needed data is not in the cache, it will be fetched from the repository. An index that only contains the most frequently searched data is called a “partially mounted index”.
If all the results are in the cache, the search will take milliseconds. If data needs to be fetched, the results would need a couple of seconds to return while the repository is being optimized for search.
Manual mounting with a fully mounted index
Now, let’s look at how manual mounting works with a fully mounted index.
The first thing to do is to configure a snapshot repository. It is recommended to use a cloud provider for data resiliency, but we can use local storage for testing purposes.
In this example, we will create a repository named local_repo.
Step 1: Create the index
POST test_mount/_doc
{
"name": "I will live in a repository"
}Step 2: Create the snapshot
PUT _snapshot/local_repo/test_mount_snapshot
{
"indices": "test_mount"
}Step 3: Mount the index from the snapshot
POST /_snapshot/local_repo/test_mount_snapshot/_mount?wait_for_completion=true
{
"index": "test_mount",
"renamed_index": "test_mount_recovered",
"index_settings": {
"index.number_of_replicas": 0
}
}If you don’t set the “index.routing.allocation.include._tier_preference” under index_settings, it will be set to “data_cold,data_warm,data_hot”, meaning it will try to mount in cold tier nodes, and if there are no cold nodes available it will try with warm and then hot.
Step 4: Search the new index
GET test_mount_recovered/_search
After mounting the index from a snapshot, we don’t need replicas for data resilience as a full copy will be stored in the repository. However, if replicas are required for speed improvement, we can add some as well.
If both the data node index and the repository fails, then the data is lost. All major public cloud providers typically offer very good protection against data loss or corruption. If you manage your own repository storage, then you are responsible for its reliability.
Manual mounting with a partially mounted index
Partially mounted indices are designed for the frozen storage tier and need a shared cache configured across the nodes. Partially mounted indices are only allocated to nodes that have a shared cache.
There are two settings for partially mounted indices:
- xpack.searchable.snapshot.shared_cache.size: Space of the disk dedicated to this purpose. It defaults to 90% of the disk for frozen tier configured nodes. This value can be a percentage or disk size.
- xpack.searchable.snapshot.shared_cache.size.max_headroom: Max headroom to maintain. If shared_cache.size is not set, it defaults to 100GB, otherwise to -1 (not set). You can only use this setting if the shared_cache.size is set to a percentage.
For shared_cache.size: 90%, and shared_cache.size.max_headroom: 100GB
A 2TB disk will have 1.9TB of cache (net 95% because of the 100GB max headroom).
A 200GB disk will have 180GB of cache (net 90%).
For production, the recommendation is to have dedicated frozen nodes, configuring the following in elasticsearch.yml:
node.roles: [ data_frozen ]
For Elastic Cloud, please see this guide on how to use the pricing calculator, which refers to creating frozen data tier nodes.
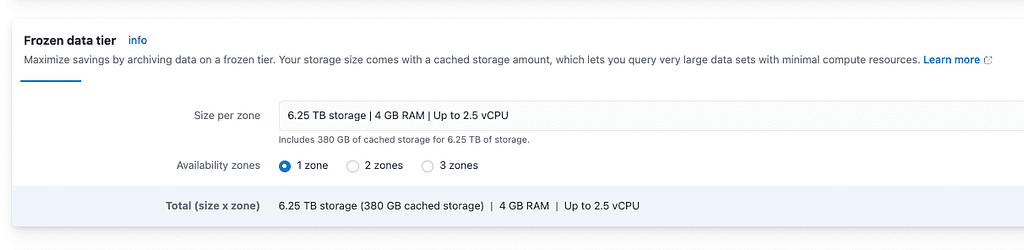
From here, we can see there is 380GB of cached storage and 6.25TB of available space in the data repository.
To use this cache in a partially mounted index, we follow a similar process as for fully mounted, you just need to specify in the mount creation query:
POST /_snapshot/local_repo/test_mount_snapshot/_mount?storage=shared_cache
{
"index": "test_mount",
"renamed_index": "test_mount_partial",
"index_settings": {
"index.number_of_replicas": 0
}
}Now, when you run a search against this new index, it will populate from the repository and keep the most frequently searched data in the cache. It will also clean/repopulate based on subsequent searches.
The differences between fully and partially mounted indices
The differences between fully and partially mounted indices are summarized in the following table:
| Fully mounted index | Partially mounted index |
|---|---|
| Contains all the snapshot data | Contains the most frequently searched data |
| No shared cache | Shared cache across data_frozen nodes |
| Used in cold storage scenarios | Used in frozen storage scenarios |
| Data persist on restarts | Data flush on restarts |
Conclusion
Searchable snapshots extend the functionality of regular repository-based snapshots by allowing data exploration.
The cold data tier leverages snapshot full mounting to go without replicas for data resilience. The frozen data tier uses partial mounting and shared cache to take cost savings and storage efficiency to the next level.