
Quick links
Background
AWS UltraWarm is an AWS OpenSearch service feature that provides a cost-effective way to store large amounts of time-based (non-mutable) data using smart caching technologies to improve performance.
UltraWarm instances will not have the disk overhead that Linux-reserved space, OpenSearch Service-reserved space, or replica disks need (as S3 has high availability features under the hood). This means that every GB you get can be used to store primary shards. S3 is resistant by design and abstracts away any other disk considerations like service or operating system.
In this article, we explain the prerequisites required for UltraWarm and how it can be used as a cost-saving storage solution.
Prerequisites
There are some conditions your cluster needs to meet to be able to utilize UltraWarm nodes:
- UltraWarm requires OpenSearch or Elasticsearch 6.8 or higher.
- Dedicated master nodes are needed.
- The domain cannot use T2 or T3 instances for data nodes.
- If the index uses kNN (index.knn: true), it can’t be moved to warm storage.
- Users need to have the ultrawarm_manager role to use OpenSearch Dashboards.
Creating the UltraWarm role
In some cases, the ultrawarm_manager role may not exist, so you must create it manually using the following configurations:
Action Groups
| Group name | Permissions |
|---|---|
| ultrawarm_cluster | - cluster:admin/ultrawarm/migration/list - cluster:monitor/nodes/stats |
| ultrawarm_index_read | - indices:admin/ultrawarm/migration/get - indices:admin/get |
| ultrawarm_index_write | - indices:admin/ultrawarm/migration/warm - indices:admin/ultrawarm/migration/hot - indices:monitor/stats - indices:admin/ultrawarm/migration/cancel |
Then create the ultrawarm_manager role with the following settings:
Cluster permissions: ultrawarm_cluster, ultrawarm_monitor
Index: *
Index permissions: ultrawarm_index_read, ultrawarm_index_write, indices_monitor
After creating the role, you can use role mappings to apply it to the users who will interact with the UltraWarm-based indices.
To learn more about users and permissions in OpenSearch, you can read our article on the subject here.
How to use UltraWarm in OpenSearch
To start using UltraWarm, you first need to enable the feature in the OpenSearch service console when creating the domain. You can also add UltraWarm features to existing domains if they meet the prerequisites listed above.
To start using UltraWarm, you first need to enable the feature in the OpenSearch service console when creating the domain. You can also add UltraWarm features to existing domains if they meet the prerequisites listed above.
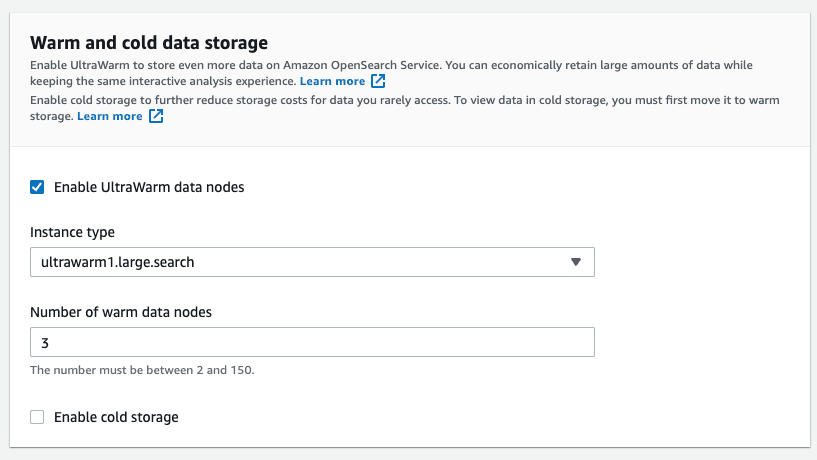
You must also select the option “enable dedicated master nodes.”
There is also an option to enable “cold storage” which is 100% stored in S3. After you save data there, you need to restore it to a warm node before being able to search it again.
Cold storage is UltraWarm but without compute capacity attached to it; therefore, any amount of data can be stored in cold storage. When you need to query cold data, you can selectively attach it to existing UltraWarm nodes.
Let’s start creating an index and adding some documents to it:
POST warm_index/_doc
{
“@timestamp”: “2022-09-09”,
“user”: “Gustavo Llermaly”
}Manually Moving Indices
To manually move indices, we can use the following command:
POST _ultrawarm/migration/warm_index/_warm
Note that the index must be green for the migration to succeed.
To get the status of the migration, we can use:
GET _ultrawarm/migration/warm_index/_status
To list warm indices, use:
GET _warm GET _cat/indices/_warm
To move the index back to hot storage, use:
POST _ultrawarm/migration/warm_index/_hot
Canceling migration
Migrations work in a queue. If a migration hasn’t started yet, you can remove it from the queue, using:
POST _ultrawarm/migration/_cancel/warm_index
Automatically moving indices
The recommended way to work with warm storage is not to move indices manually, but to use ISM (Index State Management) policies instead.
You will now see your hot and warm indices in different sections:
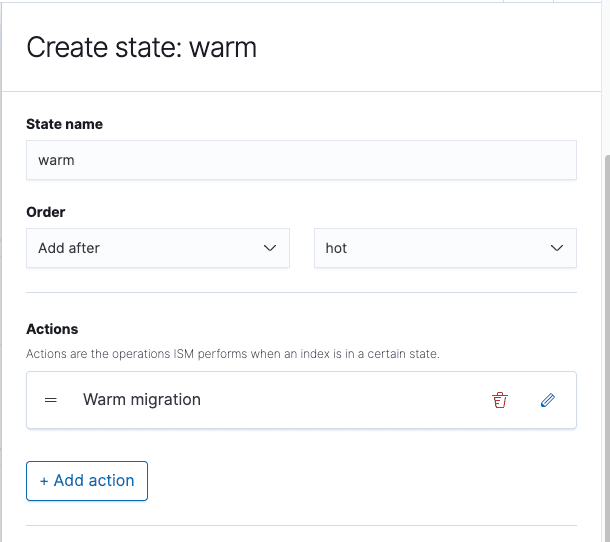
You can go ahead and create a new ISM Policy or edit an existing one and add the “warm migration” action to the warm state.
The following JSON shows the example hot/warm policy from our guide on setting up hot/warm architecture for ISM. But now, in addition to reducing replicas, it is migrating the data to warm storage:
{
"policy": {
"description": "Hot/Warm/Delete example",
"schema_version": 1,
"error_notification": {
"channel": {
"id": "tmHzgYEB62Ttjfftxmj-"
},
"message_template": {
"source": "Index {{ctx.index}} failed",
"lang": "mustache"
}
},
"default_state": "hot",
"states": [
{
"name": "hot",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"rollover": {
"min_index_age": "30d",
"min_primary_shard_size": "50gb"
}
}
],
"transitions": [
{
"state_name": "warm",
"conditions": {
"min_rollover_age": "7d"
}
}
]
},
{
"name": "warm",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"replica_count": {
"number_of_replicas": 0
}
},
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"warm_migration": {}
}
],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_rollover_age": "15d"
}
}
]
},
{
"name": "delete",
"actions": [
{
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "1m"
},
"notification": {
"channel": {
"id": "tmHzgYEB62Ttjfftxmj-"
},
"message_template": {
"source": "Index: {{ctx.index}} Deleted",
"lang": "mustache"
}
}
}
],
"transitions": []
}
],
"ism_template": [
{
"index_patterns": [
"datalogs-*"
],
"priority": 100
}
]
}
}The order of the actions is important here. If you execute the warm_migration action before the replica_count, the policy will fail.
Conclusion
AWS OpenSearch service offers a simple way to save costs by storing less frequently searched data in an optimized storage tier.
The main advantages compared to a regular node are the cost per storage unit and the ability to prescind the replicas as UltraWarm storage is calculated based on the primary shard usage. Also, the entire node capacity can be used to store data, whereas, in a hot node, overhead is incurred on things like Linux-reserved space and OpenSearch Service-reserved space.
The tradeoff for lower cost is search performance: queries may be slower when using UltraWarm nodes compared to hot nodes given the cache UltraWarm uses, and hot nodes have more hardware resources in general. Nevertheless, if you can accept that tradeoff, UltraWarm could be a good cost-saving solution for you.