
Quick links
Overview
In a previous series of articles, we delved deep into the vast topic of semantic search and how that was designed and implemented in both OpenSearch and Elasticsearch. The second and third articles focused on OpenSearch while the fourth and fifth articles handled Elasticsearch. If you’ve been through all those articles, you might have felt overwhelmed by the substantial amount of information to digest. Our main goal in this article is to put both implementations face to face and compare them so you can make a more informed choice.
So, without further ado, let’s dive right into our comparative analysis of vector search as implemented by OpenSearch and Elasticsearch.
Availability
Vector search has been available since version 1.0 in OpenSearch and version 8.0 in Elasticsearch. If your cluster is currently running an older version, you’ll need to upgrade it first.
In OpenSearch, vector search is implemented by means of two plugins, namely the k-NN plugin available since version 1.0, and the Neural Search plugin available since version 2.9. Both of these plugins are bundled into the official distribution and work out of the box, so there is no need to install them separately. In Elasticsearch, vector search is available natively and works out of the box as well.
Since 8.12, Elastic Cloud provides a new hardware profile on AWS optimized for vector search use cases. There is no such facility on the AWS OpenSearch service, even though it would be possible to select the same instance types in order to mimic the same hardware configuration, but that would have to be done manually.
Mapping
Supported engines and algorithms
In OpenSearch, vector indexing is highly configurable thanks to the variety of available vector engines, such as Lucene, Faiss, and NMSLIB, which mainly support two different algorithms: Hierarchical Navigable Small Worlds (HNSW) and Inverted File Index (IVF). Elasticsearch currently only supports the Lucene engine and the Hierarchical Navigable Small Worlds indexing and search algorithm, although IVF support is in the works.
Supported similarity metrics
Regarding distance and similarity functions, OpenSearch supports all functions presented here, namely L1 distance, L2 distance, Linf distance, cosine similarity, and dot product similarity. Elasticsearch doesn’t support them all, but it does support the main ones, i.e., L2 distance, cosine similarity, dot product similarity and maximum inner product similarity.
In 8.12, Elasticsearch has introduced support for Fused Multiply-Add to drastically speed up vector similarity computations, and hence reduce the query time.
Vector field type and dimensions
A dense vector field can be defined using the `knn_vector` mapping type in OpenSearch and the `dense_vector` mapping type in Elasticsearch.
Sparse vector fields can be defined using the `rank_features` mapping type in both OpenSearch and Elasticsearch, although Elasticsearch also provides the `sparse_vector` mapping type.
Up until Elasticsearch 8.11, dense vectors could only be of type `hnsw`. Since 8.12, a new type called `int8_hnsw` has been introduced, and supports scalar quantization out of the box, which allows to reduce memory consumption by 75% at the cost of a small storage increase.
OpenSearch supports up to 16000 dimensions, while Elasticsearch supports 1024 dimensions up to version 8.9.2. As of version 8.10.0, Elasticsearch has increased the number of supported dimensions to 2048 in order to allow OpenAI embeddings vectors with 1536 dimensions to be indexed and searched. As of version 8.11.0, the number of dimensions has been further increased to 4096, and might be further increased in future versions as the need arises. So, depending on the deep learning model you are using, the choice might already be clear to you.
Figure 1, below, shows the main differences between the vector field mapping definitions in OpenSearch and Elasticsearch.
Figure 1: Mapping differences
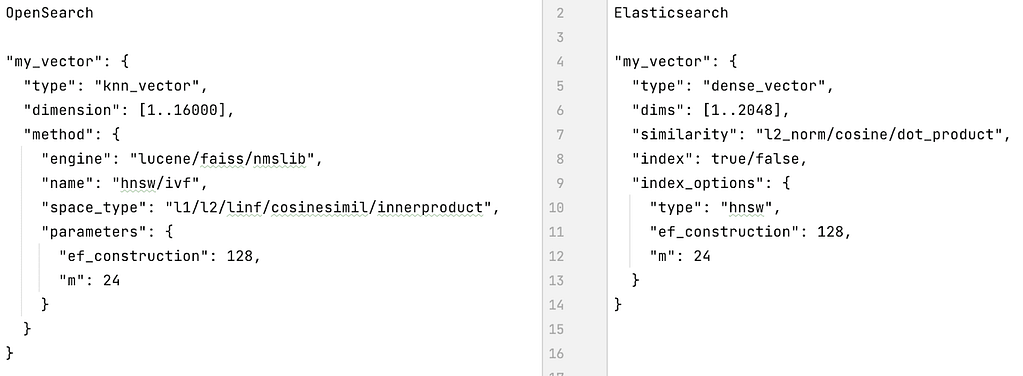
OpenSearch also allows you to define your vector fields using either an existing pre-trained model or a custom model that you can train on your own data with the desired indexing engine and algorithm. Elasticsearch doesn’t provide such a feature (yet).
Index settings
A big difference between OpenSearch and Elasticsearch is that OpenSearch requires you to specify at index creation time that you’re going to use the index for k-NN searches (by configuring `index.knn: true` in the index settings). Elasticsearch, however, allows you to decide whether each vector field should be indexed or not (by setting `index: true/false` in the vector field definition), which is a bit more flexible.
An important implication of this is that if you have several vector fields in your index (e.g., one for text embeddings and another for image embeddings), in OpenSearch they will all be indexed, whereas in Elasticsearch you get to decide which ones will be. This can have an impact on the size of your index.
Figure 2, below, shows how OpenSearch forces all vector fields to be either indexed or not and how Elasticsearch moves that constraint to the field level.
Figure 2: Settings differences

Embeddings vector generation
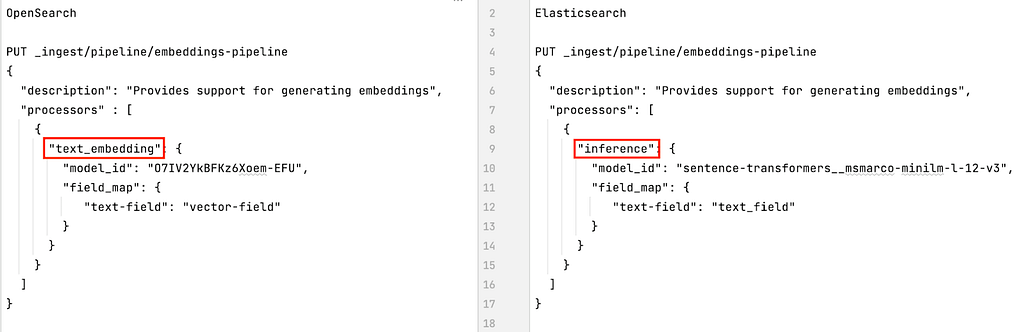
If you are not using an ad hoc library or API to generate your embeddings vectors (e.g., OpenAI Embeddings API or Cohere), both OpenSearch and Elasticsearch will provide you with an ingest pipeline processor that will help you do it on the fly. Those ingest processors are called `text_embedding` in OpenSearch and `inference` in Elasticsearch, and both can be set up in a similar way.
Figure 3, below, shows how the OpenSearch and Elasticsearch ingest processors for generating embeddings are similar apart from their names.
Figure 3: Ingest processors for generating embeddings
Queries
When the time comes to query your vector data, there are also some big differences between OpenSearch and Elasticsearch. For example, in Elasticsearch it is not possible to change the `search_type` when performing a vector search, it is always set to `dfs_query_then_fetch`, which means that term frequencies are computed globally across all shards and not at the shard level like normal. That leads to more accurate scoring but slower searches. Since OpenSearch went the way of score normalization, as we have seen here, it doesn’t have that constraint.
Exact vector search
Both OpenSearch and Elasticsearch allow you to run an exact vector search using the `script_score` query with a query and a custom Painless script to measure the distance between vectors. OpenSearch Painless provides support for L1 distance (`l1Norm`), L2 distance (`l2Squared`), and cosine similarity (`cosineSimilarity`). Elasticsearch Painless supports the same functions and the dot product similarity function (`dotProduct`) as well.
In addition, OpenSearch allows you to run the `script_score` query with a built-in script called `knn_score`, which takes as parameters the vector field name, the query vector, and the similarity function to use. The available similarity functions are L1 distance (`l1`), L2 distance (`l2`), Linf distance (`linf`), cosine similarity (`cosinesimil`), dot product similarity (`innerproduct`), and another one that we haven’t presented so far called Hamming bit (`hammingbit`).
k-NN vector search
Approximate nearest neighbor (ANN) searches are also supported by both OpenSearch and Elasticsearch. OpenSearch provides two specific DSL queries called `knn` and `neural` (which encapsulates a `knn` query internally). Elasticsearch provides a search option called `knn` that is located at the same level as the `query` section. So, in OpenSearch, lexical and k-NN queries are all located inside the `query` section, whereas in Elasticsearch, they are siblings. As of 8.12, Elasticsearch also provides a `knn` search query, whose main goal is to provide more advanced support for hybrid search. If you’re keen on learning the subtle differences between the `knn` search option and the `knn` search query, you can head over to another Elastic Search Labs article on this topic.
If you have several vector fields to query, it is possible to specify several k-NN queries in both OpenSearch (using several `knn` and `neural` queries) and Elasticsearch (using a `knn` search option array since version 8.7).
Since no one wants to run vector searches on a billion-vector data set, both OpenSearch and Elasticsearch provide support for filtering vector searches. The way the filtering is applied is pretty similar in both cases. In OpenSearch, filtering is currently supported by the Lucene and Faiss vector engines. NMSLIB doesn’t support it yet, but since they implemented filtering a while ago, it might become available at some point. Since Elasticsearch is also based on the Lucene engine, filtering is de facto supported. On the upside, Elasticsearch also allows users to specify a minimum expected similarity when performing filtered k-NN searches, which OpenSearch doesn’t.
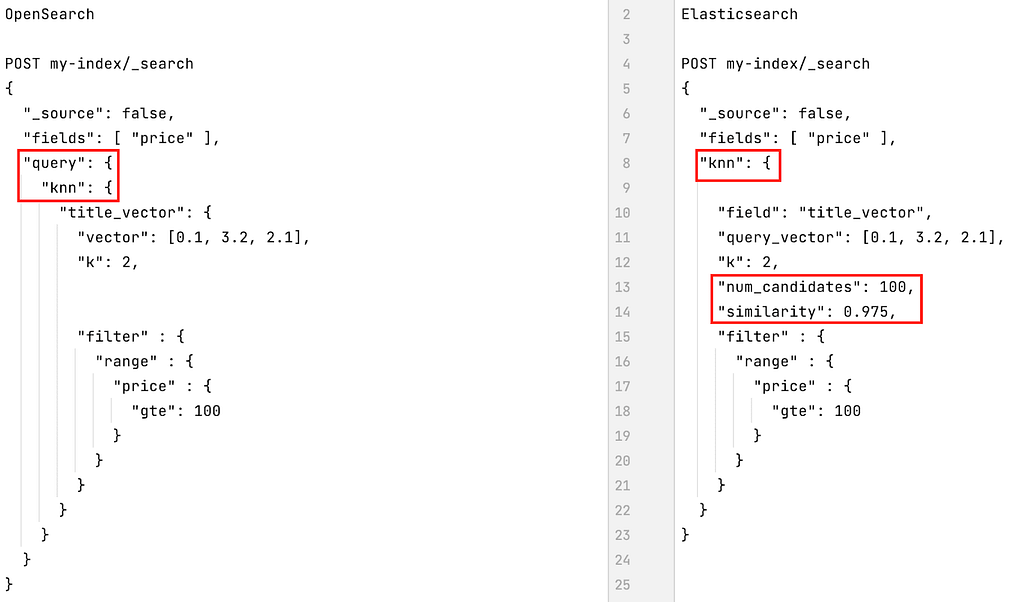
Figure 4, below, shows what k-NN search queries in OpenSearch and Elasticsearch look like.
Figure 4: k-NN search queries in OpenSearch and Elasticsearch
Hybrid search
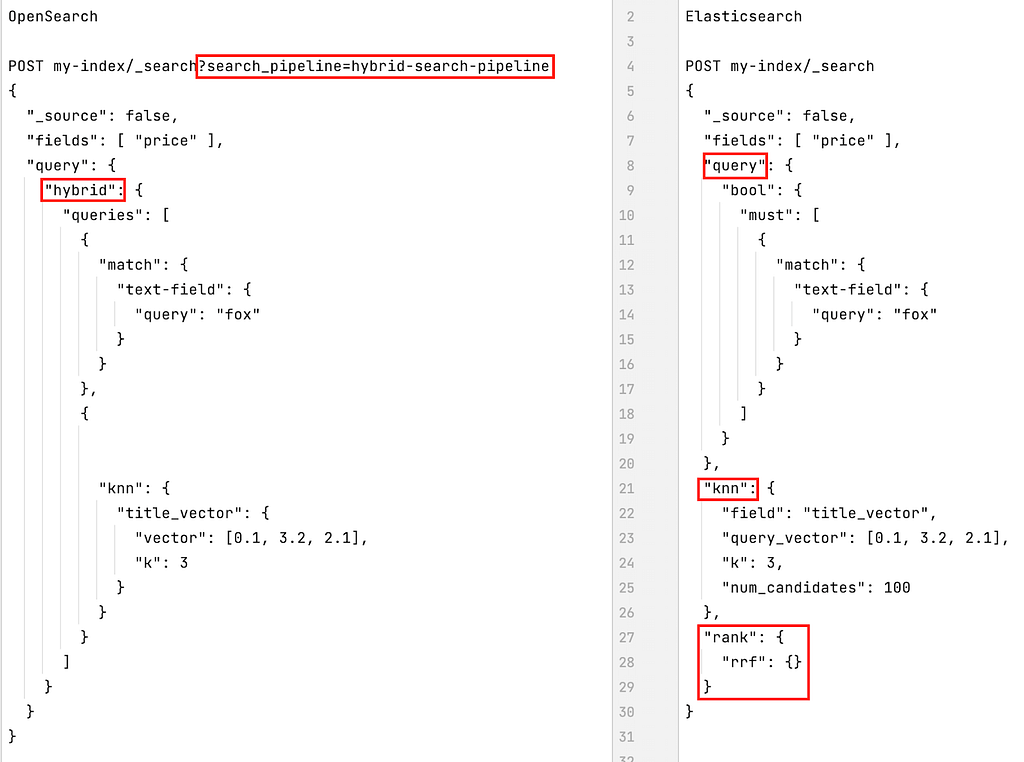
For hybrid searches where lexical and vector search queries are mixed together, both solutions have taken different approaches. OpenSearch provides a specific DSL query called `hybrid` that can contain an array of up to five lexical search queries (e.g., `match`) and vector search queries (e.g., `knn` or `neural`). Running a hybrid search query requires the use of a search pipeline normalization processor that normalizes the scores of all the result sets and reranks them globally using a parametrized Convex Combination method.
Elasticsearch implements three types of hybrid search. The first one is a mix of a lexical query specified in the `query` search option and a vector search query (or an array thereof) specified in the `knn` search option.
The second one consists of mixing regular lexical search queries and filters with the new `knn` search query available since 8.12.
The third one introduces a new search option called `sub_searches` which also contains an array of search queries that can be of a lexical (e.g., `match`) or semantic (e.g., `text_expansion`) nature.
When running either of these hybrid types in Elasticsearch, the query payload can also include a `rank` section that specifies the method for combining and ranking the different lexical and semantic result sets. At this point, only `rrf` can be specified, in which case the Reciprocal Rank Fusion method will be used. If `rank` is omitted, then the Convex Combination method will be used.
Figure 5, below, shows what hybrid search queries in OpenSearch and Elasticsearch look like. Note that the Elasticsearch hybrid search query shown in the figure is an example of the first type described above.
Figure 5: Hybrid search queries
Performance
As you can imagine, comparing the performance of vector search in OpenSearch and Elasticsearch is a big job, hence we’ll rely on the official benchmarks published on the official ANN Benchmarks website. We will focus on a specific data set contributed by Zalando called Fashion MNIST (784 dimensions), on which both OpenSearch and Elasticsearch have been benchmarked.
The results can be seen here, where `opensearchknn` denotes OpenSearch performance and `luceneknn` represents Elasticsearch performance. Many different aspects have been measured, e.g., recall vs. queries per second and recall vs. index size, among others. Feel free to check those benchmarks out in order to get a better idea of how they perform comparatively.
Short summary
As you can see, even though OpenSearch and Elasticsearch base themselves on the same vector engine (Apache Lucene), their vector search implementations, even if similar, differ in many ways. Also, as the topic of semantic search is a fast-paced field, there are many ongoing enhancements being worked on in both OpenSearch and Elasticsearch. Before choosing either of them, it’s worthwhile taking time to look at the links in the previous sentence to see where each of the technologies is heading as that might have an impact on your future business needs.
Finally, we have summarized our comparative analysis of the current state of vector search in OpenSearch and Elasticsearch in Table 1, below. The Elasticsearch features listed in the table are available with the Free license unless otherwise noted.
Table 1: Vector search in OpenSearch and Elasticsearch compared
| OpenSearch | Elasticsearch | |
|---|---|---|
| Availability | Version 1.0 | Version 8.0 |
| Deliverable | kNN and Neural Search plugins | Natively |
| Engines / Algorithms | Lucene, Faiss, NMSLIB / HNSW, IVF | Lucene / HNSW |
| Mapping types | `knn_vector` and `rank_features` Field can be defined using a pre-trained or custom model | `dense_vector`, `rank_features` and `sparse_vector` |
| Dimensions | Max 1024 for Lucene Max 16000 for Faiss / NMSLIB | Max 1024 (until 8.9.2) Max 2048 (from 8.10.0) Max 4096 (from 8.11.0) |
| Similarity | L1, L2, Linf, cosine, dot product | L2, cosine, dot product, max inner product |
| Settings | kNN is enabled at index level with `index.knn: true` | kNN is enabled at field level with `index: true/false` |
| Embeddings | Can be generated with the `text_embedding` processor | Can be generated with the `inference` processor |
| Exact kNN | Supported by `script_score` query and custom script with L1, L2, and cosine similarity functions Supported by `script_score` query and built-in `knn_score` script with L1, L2, Linf, cosine, dot product, and Hamming bit similarity functions | Supported by `script_score` query and custom script with L1, L2, cosine and dot product similarity functions |
| Approx. kNN | `knn` and `neural` DSL queries + additional filters | `knn` search option + additional filter and expected similarity |
| Hybrid | `hybrid` DSL query with search pipeline normalization processor At most five lexical and vector queries combined | `query` and `knn` search options or `knn` search query with additional `rank` method `sub_searches` search option with an array of lexical and `text_expansion` queries and `rank/rrf` method Unbounded number of lexical and vector queries |
| Hybrid scoring | Convex Linear Combination | Convex Linear Combination Reciprocal Rank Fusion |
| Performance | opensearchknn benchmark | luceneknn benchmarks |
Let’s conclude
We covered quite a lot of ground in this succinct, yet pretty dense, article. We’ve reviewed all the main differences to be aware of when considering OpenSearch or Elasticsearch as your vector engine. They both share some aspects in common, mainly the fact that they both use Apache Lucene as their indexing and search engine. They also mostly support the same distance and similarity functions.
However, the way they have implemented vector search can differ quite a bit, especially when it comes to hybrid search where lexical and vector search queries are mixed together and need to be rescored on the same scale.
We hope that this article will help you make the right choices when implementing vector search in your applications to support your business use cases. If you need to dig deeper into any of the topics summarized above, feel free to check out the article series that introduces all those topics in more detail.