
Quick Links
Introduction
Natural language processing (NLP) has undergone a transformative evolution in recent years, transitioning from traditional linguistic rules and machine learning techniques to embracing the power of deep learning. Elastic Stack has embraced this shift by incorporating deep learning NLP features, inspired by the success of pre-trained language models like BERT.
To enable these capabilities, Elasticsearch utilizes libtorch, an underlying native library for PyTorch. These machine learning features are designed to work seamlessly with TorchScript representations of trained models, facilitating efficient deployment and utilization.
Once a model is deployed to the Elasticsearch cluster, users can harness its power to perform inference on incoming data. NLP supported operations include extracting information through tasks, such as named entity recognition (NER), text classification, and text embedding, allowing users to enrich documents with models output inferences.
Definition
NLP is a field of artificial intelligence (AI) that focuses on the interaction between computers and humans through natural language. This encompasses both written and spoken language, allowing machines to comprehend, interpret, and generate human-like text.
NLP is a mix of computational linguistics, rule-based language modeling, and advanced technologies such as statistical, machine learning, and deep learning. This integration empowers computers to comprehend and interpret human language expressed through text or voice, capturing not just the literal meaning but also the underlying intent and sentiment of the speaker or writer. Its influence extends to various computer applications, including language translation, responsive voice-command systems, information enrichment, and summarization of texts.
Machine Learning & Deep Learning
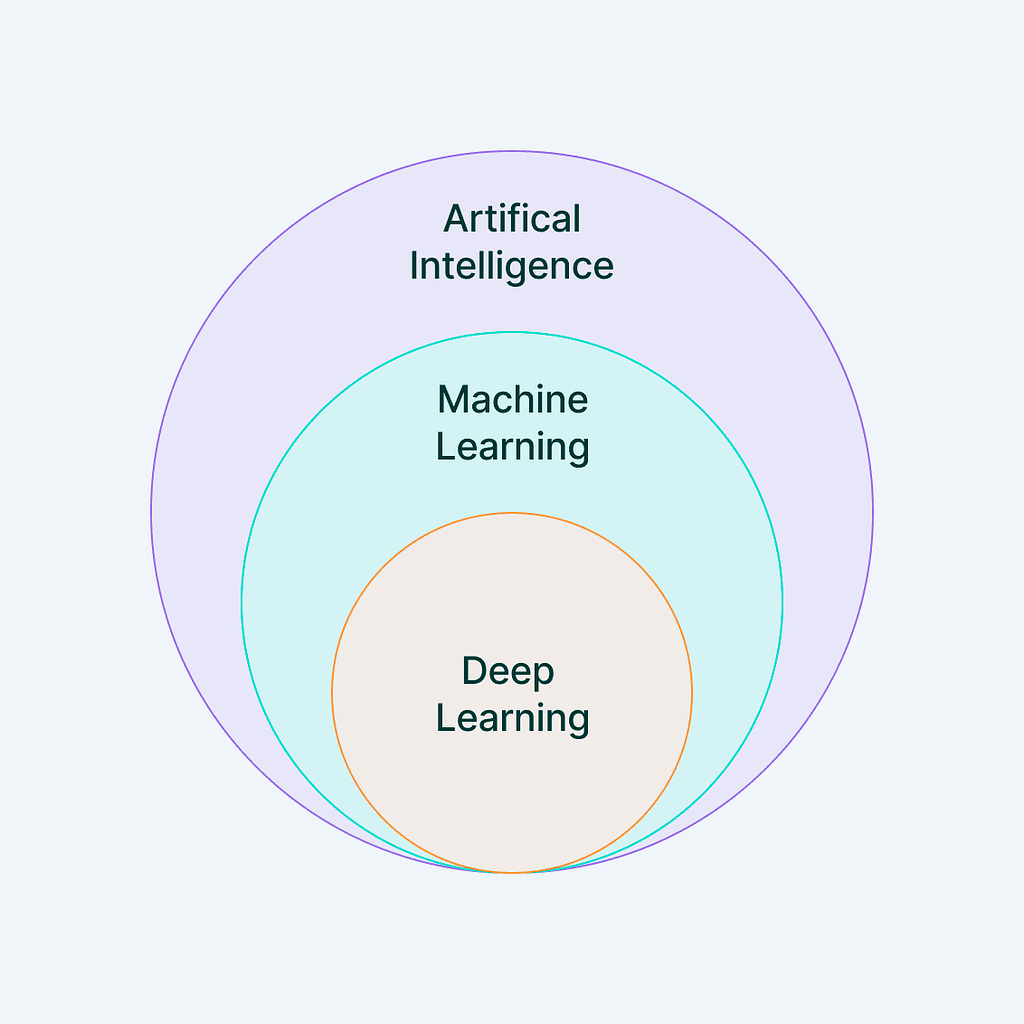
Machine Learning is tech lingo for computers figuring things out from data. Think of it like teaching them to do a task without having to provide step-by-step instructions. They learn by spotting patterns in the data and making predictions when they get new information.
There are two main types of learning, one where the computer gets labeled data to learn from, also called supervised, and another where it figures things out on its own, known as unsupervised.
Even a basic algorithm, like predicting income based on someone’s level of education, is Machine Learning. When users input a bunch of examples, it looks for trends, and uses these to predict things. Deep Learning is a fancy version of Machine Learning, where the computer learns from really complex data using neural networks, which are like brain-inspired algorithms. It’s like an advanced class of Machine Learning.
BERT and Other Models
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model released by Google in 2018. Since then, it has become the inspiration for many other modern models in use in the NLP space, like BART, and has proved itself to be powerful and useful.
BERT is designed to understand the context of words (Encoder) in a sentence. It does so by considering both the left and the right context of a word (Bidirectional). For example, in the sentence “I left my phone on the left side of the room,” BERT is able to understand and differentiate both meanings of the word left.
The Transformer is an architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease, for example, many words in a sentence.
Elastic supports BERT’s tokenization scheme, also called WordPiece, and transformer models that conform to the standard BERT model interface. See the full list of supported models.
Deep Learning on Elastic
Machine Learning (ML) is a paid feature of Elasticsearch. Version 8.0 introduced the ability to upload machine learning models from PyTorch — a popular ML framework. That means users now have extra tools to extract information, classify, search, compare text, and much more.
The best part is, many models are suited for a variety of tasks that are already trained, so there’s no need to reinvent the wheel and train a model from scratch. Users can simply select and import it, using Eland, from Hugging Face — a ML and data science platform and community.
Elastic Eland
Eland is a Python Elasticsearch client toolkit with a Pandas-like API. When available, it uses existing Python APIs and data structures to make it easy to switch between numpy, pandas, and scikit-learn to Elasticsearch equivalents. The data resides in Elasticsearch instead of memory, which allows Eland to access large datasets.
In order to run pre-trained NLP models tasks, Eland, with eland_import_hub_model script, enables users to import models from Hugging Face into Elasticsearch, using the create trained model API. Here’s an example:
Installing package:
python -m pip install "eland[pytorch]”
Run import script:
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
-u <username> -p <password> \
--hub-model-id $MODEL_NAME \
--startCommand explanations:
- –url: Elasticsearch cluster URL
- -u / -p: authentication if needed
- –hub-model-id: the model id we’re importing
- –task-type: Specify the type of NLP task we wish to run on Elasticsearch. We will be discussing more in detail during the next topic. Supported values are fill_mask, ner, question_answering, text_classification, text_embedding, and zero_shot_classification.
- –start: Is a command used to deploy and start the model to all available machine learning nodes, and load the model in memory on a specified cluster (–url).
Supported NLP Operations / Task Type
Elasticsearch Machine Learning can import trained models to execute the following NLP operations:
Information Extraction
A category of models which enables users to process unstructured text.
Named entity recognition (ner)
NER categorizes entities in unstructured text, offering structure and insights. Named entities usually refer to objects in the real world, such as persons, locations, organizations, etc…
Example:
Input text: “Marcos is in Florida”
Result:
...
"entities": [
{"entity": "Marcos", "class": "person"},
{"entity": "Florida", "class": "location"}
], ...Fill mask
The fill-mask task predicts a missing word in a text sequence by utilizing the context of the masked word. The goal is to predict the best word to complete the text. In practice, a special placeholder, “[MASK],” is employed to guide the model in predicting the designated word.
Input text: “In degrees Celsius and at sea level, the boiling point of water is [MASK].”
Result:
...
{
"predicted_value": "100", ...
}, ...Question answering
The question answering task is used to obtain answers by extracting information from a given text. The model tokenizes lengthy unstructured text and aims to extract an answer. This logic is illustrated in the example below:
Input:
{
"docs": [{"text_field": "The Great Barrier Reef, the world's largest coral reef system, is located in the Coral Sea off the coast of Queensland, Australia."}],
"inference_config": {"question_answering": {"question": "Where is the Great Barrier Reef located?"}}
}, ...Result:
{
"predicted_value": "Australia", ...
}Text Classification
NLP tasks to classify or label unstructured input text.
Text classification involves assigning input text to the specific class that best characterizes it. The classes are determined by the model and the training dataset. There are two primary types of classifications based on the number of classes: binary classification, with exactly two classes, and multi-class classification, with more than two classes.
It is worth mentioning that this typeof text classification is trained on categories we’ll be using, for example, if we train text classification to classify texts as positive or negative sentiments, as we explain in this sentiment analysis article, both classification and inference will use the same classes:
Input text: “This movie was awesome!”
Result:
"inference_results": [
{"predicted_value": "POSITIVE", ...}
]And the same happens on multi-class classifications, where the model is trained to identify classes we’re looking for.
Input text: “The characters in this film navigate complex relationships and intricate plots.”
Result:
"inference_results": [
{"predicted_value": "Drama", ...}
]Zero-shot text classification
The zero-shot classification task enables text classification without training the model on predefined classes. Instead, users specify the classes during deployment or at inference time.
It utilizes a model trained on a broad dataset, possessing general language understanding, and assesses how well the provided labels align with the text. This approach enables the analysis and classification of input text even in scenarios where there’s insufficient training data to train a specific text classification model, example:
Input:
{
"docs": [{"text_field": "NASA Launches Psyche, a Mission to Explore a Metal Asteroid"}],
"inference_config": {
"zero_shot_classification": {
"labels": ["News", "Opinion", "Business", "Science", "Health", "Sports", "Arts"]
}
}
}Result:
...
{
"predicted_value": ["Science", "News"], ...
}, ...Language identification
A built-in Elastic model that infers text language. For a list of supported languages please refer to the official documentation.
Text Comparison and Search
Search and compare refers to operations using embeddings/vectors, which can be used to search in unstructured text or to compare different pieces of text.
Text embedding is a task that generates a numerical representation, known as an embedding, for a given text. The machine learning model transforms the text into numerical values, creating a vector. Texts with similar meanings have comparable representations, enabling the determination of semantic relationships — whether texts are similar, different, or even opposite — through a mathematical similarity function. The task specifically focuses on creating the embedding, which can be stored in a dense_vector field for used during searches. For instance, these vectors can be applied in a k-nearest neighbor (kNN) search. For more details and examples, check out the How to setup vector search in Elasticsearch guide.
Input text:
{
docs: [{"text_field": "The quick brown fox jumps over the lazy dog."}]
}Result:
{
"predicted_value": [0.293478, -0.23845, ..., 1.34589e2, 0.119376]
}Then, the output array can be used in many different operations. for example, to embed images, to get an array representation of the image, and to search for similar images using knn query:
Input documents – Using arrays with simple values, for a better understanding:
{ "byte-image-vector": [10, 20, 30, 40, 50, 60, ...], "title": "full moon 1" }
{ "byte-image-vector": [1, 2, 3, 4, 5, 6, ...], "title": "full moon 2" }
{ "byte-image-vector": [1, 200, 3, 400, 5, 600, ...], "title": "full moon 3" }
...KNN Search:
POST index_name/_search
{
"knn": {
"field": "byte-image-vector",
"query_vector": [10, 20, 3, 4, 5, 6, ...],
"k": 2,
"num_candidates": 100
},
"fields": [ "title" ]
}The array (image) we’re looking for on this query doesn’t match 100% with any of the ingested documents. However, by using score functions, Elasticsearch will return the 2 images (k) that are the most similar to the search input.
Conclusion
The integration of deep learning into NLP within the Elastic Stack, leveraging technologies like libtorch and TorchScript, marks a significant advancement in language understanding and model deployment.
Elastic Eland serves as a bridge between Elasticsearch and models built on top of PyTorch, allowing for seamless utilization of deep learning capabilities and the power of Elastic Stack during data processing and searches.