
Quick links
- Overview
- Background
- How to set up k-NN
- Beyond k-NN
- Glimpse into some upcoming related topics
- Let’s conclude
Overview
This article is the fourth in a series of five that dives into the intricacies of vector search (aka semantic search) and how it is implemented in OpenSearch and Elasticsearch.
The first part: A Quick Introduction to Vector Search, was focused on providing a general introduction to the basics of embeddings (aka vectors) and how vector search works under the hood. The content of that article was more theoretical and not oriented specifically on OpenSearch, which means that it was also valid for Elasticsearch as they are both based on the same underlying vector search engine: Apache Lucene.
Armed with all the vector search knowledge learned in the first article, the second article: How to Set Up Vector Search in OpenSearch, guided you through the meanders of how to set up vector search in OpenSearch using either the k-NN plugin or the new Neural Search plugin that was recently made generally available in 2.9.
In the third part: OpenSearch Hybrid Search, we leveraged what we had learned in the first two parts and built upon that knowledge by delving into how to craft powerful hybrid search queries in OpenSearch.
This fourth part is similar to the second one but specifically focuses on how to set up vector search and execute k-NN searches in Elasticsearch.
The fifth part: Elasticsearch Hybrid Search, will be similar to the third one but will be focused on running hybrid search queries in Elasticsearch.
Some background first
In the second article, we explained in detail how vector search was implemented in OpenSearch by means of two different plugins, namely k-NN and Neural Search. Given that OpenSearch was forked from Elasticsearch (in 7.10.2), you might think that OpenSearch inherited its vector search features from Elasticsearch, but that’s not the case at all. OpenSearch inherited its k-NN feature from the merged OpenDistro project managed by Amazon, who developed and released the k-NN plugin way before vector search was even a dream in Elasticsearch.
However, even though Elasticsearch did not support vector search up until version 8.0 with the technical preview of the `_knn_search` API endpoint, it has been possible to store vectors using the `dense_vector` field type since the 7.0 release. At that point, vectors were simply stored as binary doc values but not indexed using any of the algorithms that we presented in our first article. Those dense vectors constituted the premises of the upcoming vector search features in Elasticsearch.
In light of this, as we’ll see shortly, Elasticsearch and OpenSearch vector search implementations are very different even though they are both based on the same concepts, algorithms, and techniques that we’ve seen so far. If you’re interested in diving more into the discussions that led to the current implementation of vector search in Elasticsearch, you can refer to this issue, which details all the hurdles that the Elastic folks had to jump over in order to bring this feature to market. Very briefly, since Elasticsearch already made heavy use of Lucene as their underlying search engine, they also decided to utilize the same technology as their vector engine, and they explained the rationale behind that decision in a very transparent way.
With history matters out of the way, let’s now get to work.
How to set up k-NN
In contrast to OpenSearch where vector search is provided by means of plugins, that feature is available natively in Elasticsearch, and there’s nothing specific to install. We only need to create an index that defines at least one field of type `dense_vector`, which is where your vector data will be stored and/or indexed.
The mapping below shows a `dense_vector` field called `title_vector` of dimension 3. Dense vectors stored and indexed in this field will use the `dot_product` similarity function that we introduced in the first article in this series. It is worth noting that, in contrast to what we saw in OpenSearch, `hnsw` (i.e., Hierarchical Navigable Small Worlds) is currently the only algorithm supported by Apache Lucene for indexing dense vectors, so the `index_options` section contains configuration parameters for that algorithm. In the future, Elasticsearch might provide additional methods for indexing and searching dense vectors, but since it fully relies on Apache Lucene that will depend on what unfolds on that front.
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "dot_product",
"index_options": {
"type": "hnsw",
"ef_construction": 128,
"m": 24
}
}The table below summarizes all available configuration parameters for the `dense_vector` field type provided by Elasticsearch:
Table 1: The different configuration parameters for dense vectors
| Parameter | Required | Description |
|---|---|---|
| dims | Yes (< 8.11) No (8.11+) | The number of vector dimensions, which can’t exceed 1024 until 8.9.2, 2048 since 8.10.0 and 4096 since 8.11.0. Also, as of 8.11, this parameter is not required anymore and will default to the dimension of the first indexed vector. |
| element_type | No | The data type of the vector element values. If unspecified, the default type is `float` (4 bytes), and `byte` (1 byte) is also available. |
| index | No | Indicates whether to index vectors (if `true`) in a dedicated and optimized data structure or simply store them as binary doc values (if `false`). Until 8.10, the default value was `false` if not specified. As of 8.11, the default value is `true` if not specified. |
| similarity | Yes (< 8.11) No (8.11+) | Until 8.10, this parameter is required if `index` is `true` and defines the vector similarity metric to use for k-NN search. The available metrics are: - `l2_norm`: L2 distance - `dot_product`: dot product similarity - `cosine`: cosine similarity - `max_inner_product`: maximum inner product similarity Also note that `dot_product` should be used only if your vectors are already normalized (i.e., they are unit vectors with magnitude 1), otherwise use `cosine` or `max_inner_product`. As of 8.11, this parameter defaults to `cosine` when not specified. |
| index_options | No | Since the `hnsw` algorithm is currently the only supported one, the only available configuration parameters are `type` (default and only value is `hnsw`), `ef_construction`, and `m`. You can check the official documentation to learn about their detailed description |
As we can see in the above table, since the version 8.11 the definition of vector fields has been drastically simplified:
“title_vector”: {
“type”: “dense_vector”,
“dims”: 3, # dynamic
“index”: true, # true by default
“similarity”: “dot_product” # defaults to cosine
}
That’s all there is to it! By simply defining and configuring a `dense_vector` field, we can now index vector data in order to run vector search queries in Elasticsearch using the `knn` search option. Like OpenSearch, Elasticsearch supports two different vector search modes: 1) exact search using the `script_score` query and 2) approximate nearest neighbor search using the `knn` search option. We’re going to describe both modes next.
Exact search
If you recall from the first article of this series, where we reviewed the vector search landscape, an exact vector search simply boils down to performing a linear search, or brute-force search, across the full vector space. Basically, the query vector will be measured against each stored vector in order to find the closest neighbors. In this mode, the vectors do not need to be indexed in an HNSW graph but simply stored as binary doc values, and the similarity computation is run by a custom Painless script.
First, we need to define the vector field mapping in a way that the vectors are not indexed, and this can be done by specifying `index: false` and no `similarity` metric in the mapping:
# 1. Create a simple index with a dense_vector field of dimension 3
PUT /my-index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
},
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": false
}
}
}
}# 2. Load that index with some data
POST my-index/_bulk
{ "index": { "_id": "1" } }
{ "title_vector": [2.2, 4.3, 1.8], "price": 23}
{ "index": { "_id": "2" } }
{ "title_vector": [3.1, 0.7, 8.2], "price": 9}
{ "index": { "_id": "3" } }
{ "title_vector": [1.4, 5.6, 3.9], "price": 124}
{ "index": { "_id": "4" } }
{ "title_vector": [1.1, 4.4, 2.9], "price": 1457}The advantage of this approach is that vectors do not need to be indexed, which makes indexing much faster than having to build the underlying HNSW graph. However, depending on the size of the data set and your hardware, search queries can slow down pretty quickly as your data volume grows, since the more vectors you add, the more time is needed to visit each one of them (i.e., linear search has an O(n) complexity).
With the index being created and the data being loaded, we can now run an exact search using the following `script_score` query:
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"query": {
"script_score": {
"query" : {
"bool" : {
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
},
"script": {
"source": "cosineSimilarity(params.queryVector, 'title_vector') + 1.0",
"params": {
"queryVector": [0.1, 3.2, 2.1]
}
}
}
}
}As you can see, the `script_score` query is composed of two main elements, namely the `query` and the `script`. In the above example, the `query` part specifies a filter (i.e., `price >= 100`), which restrains the document set against which the `script` will be executed. If no query was specified, it would be equivalent to using a `match_all` query, in which case the script would be executed against all vectors stored in the index. Depending on the number of vectors, the search latency can increase substantially.
Since vectors are not indexed, there’s no built-in algorithm that will measure the similarity of the query vector with the stored ones, this has to be done through a script, and luckily for us, Painless provides most of the similarity functions that we’ve learned so far, such as:
- `l1norm(vector, field)`: L1 distance (Manhattan distance)
- `l2norm(vector, field)`: L2 distance (Euclidean distance)
- `cosineSimilarity(vector, field)`: Cosine similarity
- `dotProduct(vector, field)`: Dot product similarity
Since we’re writing a script, it is also possible to build our own similarity algorithm. Painless makes this possible by providing access to `doc[<field>].vectorValue`, which allows iterating over the vector array, and `doc[<field>].magnitude`, which returns the length of the vector.
To sum up, even though exact search doesn’t scale well, it might still be suitable for certain very small use cases, but if you know your data volume will grow over time, you need to consider resorting to k-NN search instead. That’s what we’re going to present next.
Approximate k-NN search
Most of the time, this is the mode you’re going to pick if you have a substantial amount of data and need to implement vector search using Elasticsearch. Indexing latency is a bit higher since Lucene needs to build the underlying HNSW graph to store all vectors. It is also a bit more demanding in terms of memory requirements at search time, and the reason it’s called “approximate” is because the accuracy can never be 100% like with exact search. Despite all this, approximate k-NN offers a much lower search latency and allows us to scale to millions, billions, or even trillions, of vectors, provided your cluster is sized appropriately.
Let’s see how this works. First, let’s create a sample index with adequate vector field mapping to index the vector data (i.e., `index: true` + specific `similarity`) and load it with some data:
# 1. Create a simple index with a dense_vector field of dimension 3
{
"mappings": {
"properties": {
"price": {
"type": "integer"
},
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": true, # default since 8.11
"similarity": "cosine", # default since 8.11
"index_options": {
"ef_construction": 128,
"m": 24
}
}
}
}
}# 2. Load that index with some data
POST my-index/_bulk
{ "index": { "_id": "1" } }
{ "title_vector": [2.2, 4.3, 1.8], "price": 23}
{ "index": { "_id": "2" } }
{ "title_vector": [3.1, 0.7, 8.2], "price": 9}
{ "index": { "_id": "3" } }
{ "title_vector": [1.4, 5.6, 3.9], "price": 124}
{ "index": { "_id": "4" } }
{ "title_vector": [1.1, 4.4, 2.9], "price": 1457}Simple k-NN search
After running these two commands, our vector data is now properly indexed in an HNSW graph and ready to be searched using the `knn` search option. Note that it is not a `knn` search query like in OpenSearch, but the search payload contains a `knn` section (at the same level as the `query` section you’re used to) where the vector search query can be specified, as shown in the query below:
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100
}
}In the above search payload, we can see that there is no `query` section like for lexical searches, but a `knn` section instead, whose content is very similar to that of the OpenSearch `knn` search query. We are searching for the two (`k: 2`) nearest neighboring vectors to the specified query vector.
The role of `num_candidates` is to increase or decrease the likelihood of finding the true nearest neighbor candidates. The higher that number, the slower the search but also the more likely the real nearest neighbors will be found. As many as `num_candidates` vectors will be considered on each shard, and the top k ones will be returned to the coordinator node, which will merge all shard-local results and return the top k vectors from the global results as illustrated in Figure 1, below:
Figure 1: Nearest neighbor search accuracy using num_candidates
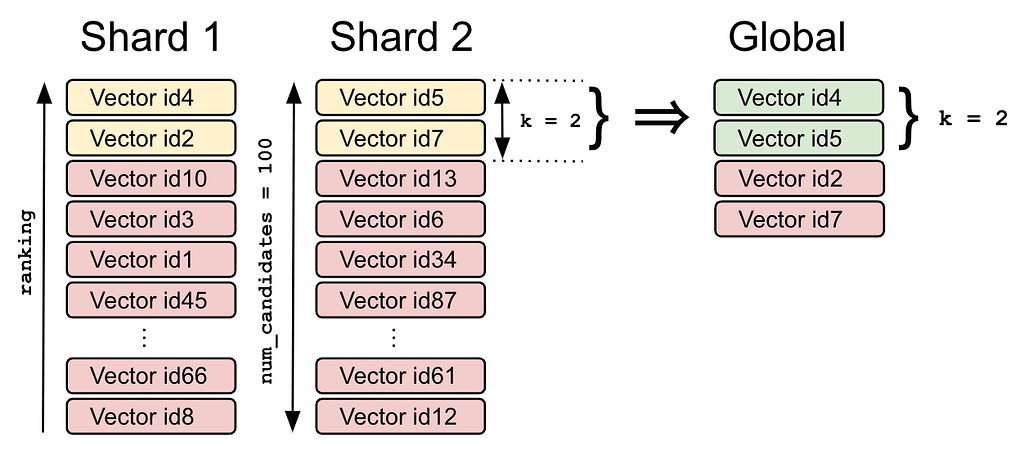
Vectors `id4` and `id2` are the k local nearest neighbors on the first shard, and `id5` and `id7` are on the second shard. After merging and reranking them, the coordinator node returns `id4` and `id5` as the two global nearest neighbors for the search query.
Several k-NN searches
If you have several vector fields in your index, it is possible to send several k-NN searches as the `knn` section also accepts an array of queries, as shown below:
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": [
{
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"boost": 0.4
},
{
"field": "content_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100,
"boost": 0.6
}
]
}As we can see, each query can take a different value of k as well as a different boost factor. The boost factor is equivalent to a weight, and the total score will be a weighted average of both scores as we saw with Convex Combination in the third article in this series.
Filtered k-NN search
Similarly to what we saw with the `script_score` query earlier, the `knn` section also accepts the specification of a filter in order to reduce the vector space on which the approximate search should run. For instance, in the k-NN search below, we’re restricting the search to only documents whose price is greater than or equal to 100.
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
}Now, you might wonder whether the data set is first filtered by price and then the k-NN search is run on the filtered data set (pre-filtering) or the other way around, i.e., the nearest neighbors are first retrieved and then filtered by price (post-filtering). It’s a bit of both actually. If the filter is too aggressive, the problem with pre-filtering is that k-NN search would have to run on a very small and potentially sparse vector space and would not return very accurate results. Whereas post-filtering would probably weed out a lot of high-quality nearest neighbors.
So, the filtering works during the k-NN search in such a way as to make sure that at least k neighbors can be returned. If you’re interested in the details of how this works, you can check out the following Lucene issue dealing with this matter.
Filtered k-NN search with expected similarity
In the previous section, we learned that when specifying a filter, we can reduce the search latency, but we also run the risk of drastically reducing the vector space to vectors that are partly or mostly dissimilar to the query vector. In order to alleviate this problem, k-NN search makes it possible to also specify a minimum similarity value that all returned vectors are expected to have. Reusing the previous query, it would look like this:
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"similarity": 0.975,
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
}Basically, the way it works is that the vector space will be explored by skipping any vector that either doesn’t match the provided filter or that has a worse similarity than the specified one up until the k nearest neighbors are found. If the algorithm can’t honor at least k results (either because of a too-restrictive filter or an expected similarity that is too low), a brute-force search is attempted instead so that at least k nearest neighbors can be returned.
A quick word concerning how to determine that minimum expected similarity. It depends on which similarity metric you’ve chosen in your vector field mapping. If you have picked `l2_norm`, which is a distance function (i.e., similarity decreases as distance grows), you will want to set the maximum expected distance in your k-NN query, that is, the maximum distance that you consider acceptable. In other words, a vector having a distance between 0 and that maximum expected distance with the query vector will be considered “close” enough to be similar.
If you have picked `dot_product` or `cosine` instead, which are `similarity` functions (i.e., similarity decreases as the vector angle gets wider), you will want to set a minimum expected similarity. A vector having a similarity between that minimum expected similarity and 1 with the query vector will be considered “close” enough to be similar.
Applied to the sample filtered query above and the sample data set that we have indexed earlier, Table 1, below, summarizes the cosine similarities between the query vector and each indexed vector. As we can see, vectors 3 and 4 are selected by the filter (price >= 100), but only vector 3 has the minimum expected similarity (i.e., 0.975) to be selected.
Table 2: Sample filtered search with expected similarity
| Vector | Cosine similarity | Price |
|---|---|---|
| 1 | 0.8473 | 23 |
| 2 | 0.5193 | 9 |
| 3 | 0.9844 | 124 |
| 4 | 0.9683 | 1457 |
Limitations of k-NN
Now that we have reviewed all the capabilities of k-NN searches in Elasticsearch, let’s see the few limitations that you need to be aware of:
- k-NN searches cannot be run on vector fields located inside `nested` documents.
- The `search_type` is always set to `dfs_query_then_fetch`, and it is not possible to change it dynamically.
- The `ccs_minimize_roundtrips` option is not supported when searching across different clusters with cross-cluster search.
- This has been mentioned a few times already, but due to the nature of the HNSW algorithm used by Lucene (as well as any other approximate nearest neighbors search algorithms for that matter), “approximate” really means that the k nearest neighbors being returned are not always the true ones.
Tuning k-NN
As you can imagine, there are quite a few options that you can use in order to optimize the indexing and search performance of k-NN searches. We are not going to review them in this article, but we really urge you to check them out in the official documentation if you are serious about implementing k-NN searches in your Elasticsearch cluster.
Beyond k-NN
Everything we have seen so far leverages dense vector models (hence the `dense_vector` field type), in which vectors usually contain essentially non-zero values. Elasticsearch also provides an alternative way of performing semantic search using sparse vector models.
They have created a sparse NLP vector model called Elastic Learned Sparse EncodeR, or ELSER for short, which is an out-of-domain (i.e., not trained on a specific domain) sparse vector model that does not require any fine-tuning. It was pre-trained on a vocabulary of approximately 30000 terms, and being a sparse model, it means that vectors have the same number of values, most of which are zero.
A quick glimpse into some upcoming related topics
As we learned in the previous article about hybrid searches in OpenSearch, combining lexical search and vector search is also possible in Elasticsearch, but that will be the subject of the next and final article of this series to be published soon.
If you are interested in other flavors of semantic search, such as Natural Language Processing (NLP), Named Entity Recognition (NER), Sentiment Analysis, Language Detection, and Text Classification, we have a few different articles coming up on those subjects, so stay tuned…
So far, we’ve had to generate the embeddings vectors outside of Elasticsearch and pass them explicitly in all our queries. Remember that when dealing with OpenSearch k-NN queries in the second article, we saw that it was possible to just provide the query text and a model would generate the embeddings on the fly? Well, the good news is that this is possible with Elasticsearch as well by leveraging a construct called `query_vector_builder`, but as there is quite some ground to cover, that will be the subject of another dedicated article to be published soon.
Let’s conclude
In this article, we delved deeply into Elasticsearch vector search support. We first shared some background on Elastic’s quest to provide accurate vector search and why they decided to use Apache Lucene as their vector indexing and search engine.
We then introduced the two main ways to perform vector search in Elasticsearch, namely either by leveraging the `script_score` query in order to run an exact brute-force search or by resorting to using approximate nearest neighbor search via the `knn` search option.
We showed how to run a simple k-NN search and, following up on that, we reviewed all the possible ways of configuring the `knn` search option using filters and expected similarity and how to run multiple k-NN searches at the same time.
To wrap up, we listed some of the current limitations of k-NN searches and what to be aware of. We also invited you to check out all the possible options that can be used to optimize your k-NN searches.
Now that we’ve seen how both OpenSearch and Elasticsearch have approached and implemented k-NN searches, you might not be clear on which way to go to support your use case and that’s perfectly understandable. You might want to check out our other article, in which we provide an in-depth comparison between them.
If you like what you’re reading, make sure to check out the other parts of this series:
- Part 1: A Quick Introduction to Vector Search
- Part 2: How to Set Up Vector Search in OpenSearch
- Part 3: Hybrid Search Using OpenSearch
- Part 5: Hybrid Search Using Elasticsearch