
Quick links
- What is a Searchable Snapshot?
- When to use searchable snapshots
- How to use searchable snapshots
- Known limitations at this stage
- Conclusion
Disclaimer: This is an experimental feature released on 2.4 and might change in the future. This guide is up to date as of March 2023.
Definition
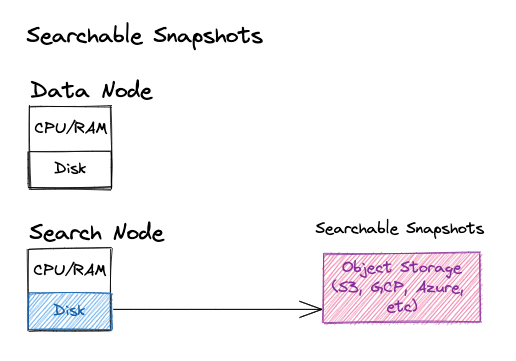
A searchable snapshot is a unique type of index, which stores data in an external storage system, instead of storing the data on the disk, the same way as a snapshot.
Searchable snapshots have been available for some time on Elasticsearch but have now been released as a feature on OpenSearch. This document only covers the OpenSearch implementation. For Elasticsearch searchable snapshots, read this guide.
Searchable snapshots are part of OpenSearch’s Storage Roadmap, a 5 phase plan aimed at fully implementing the integration of external object storage systems like AWS S3 or GCS (Google Cloud Storage) with the search clusters. This integration is a cost-effective solution that will allow users to have large quantities of long-term searchable data available.
OpenSearch definition: “Users can search snapshots in remote repositories without downloading all index data to disk ahead of time.”
This feature will leverage AWS UltraWarm, implementing it natively in OpenSearch. The benefit is that now searchable snapshot capabilities will be possible outside AWS, on top of any of the snapshot repository types (GCS, HDFS, Azure, etc).
When to use searchable snapshots
Searchable snapshots should be cheaper to store than a normal OpenSearch index. However, this comes with a few main disadvantages:
- You cannot write to a searchable snapshot
- Search latencies are slower
- The costs of constantly retrieving data from storage may outweigh the storage savings.
For this reason, searchable snapshots are well suited for holding large volumes of infrequently accessed data, which doesn’t require updating.
How to use searchable snapshots
To create a searchable snapshot index in OpenSearch follow these steps:
- Enable the feature
- Set node roles
- Create a snapshot
- Restore the snapshot as a searchable snapshot
- Search against the new index
1. Enable the feature
Go to config/jvm.options and add the following line:
-Dopensearch.experimental.feature.searchable_snapshot.enabled=true
Alternatively, set an environment variable:
export OPENSEARCH_JAVA_OPTS="-Dopensearch.experimental.feature.searchable_snapshot.enabled=true"
2. Set node role
For a node to be able to use searchable snapshots it must have the “search” role. The search role serves the following purposes:
- Requires part of the local disk to be reserved for caching remote index data
- Ensures that “remote” shards are only allocated to these nodes
In opensearch.yml
node.roles: [ search ]
This configuration will create a node with searchable snapshot capabilities.
This role enables the node to support “remote” shards, which store data in a remote repository, as the authoritative source. The index data will not be stored permanently on the local instance’s storage, but can be temporarily cached on the local disk.
3. Create a snapshot repository
To create a snapshot users need to register a repository. Follow our article for instructions.
4. Create a snapshot of an index
Create an index for demonstration purposes:
POST test_searchable_snapshot/_doc
{
"name": "I will live in a snapshot!"
}Then, users can create a snapshot of this index:
PUT _snapshot/my-repository/snapshot_name
{
"indices": "test_searchable_snapshot",
"ignore_unavailable": true,
"include_global_state": false,
"partial": false
}5. Restore the snapshot as a searchable snapshot
Now, users can restore the snapshot as a searchable snapshot index. Meaning they can search from the object storage directly, without having to go through a regular restoring process.
POST _snapshot/my-repository/snapshot_name/_restore
{
"indices": "test_searchable_snapshot",
"storage_type": "remote_snapshot",
"rename_pattern": "(.+)",
"rename_replacement": "searchable_$1",
}Note the “storage_type” parameter. By default, it is “local,” meaning the snapshot will be restored entirely in local storage. If set to remote_snapshot, it will leverage the UltraWarm capabilities and become a searchable snapshot instead.
Let’s rename the restored index, so we can compare it to the existing one.
GET /searchable_test_searchable_snapshot/_settings?pretty
To confirm the index is a searchable snapshot, it should contain the remote_snapshot storage type.
6. Search against the searchable snapshots
There is no difference between a regular search and a searchable snapshot search request.
GET searchable_test_searchable_snapshot/_search
Users should see the results coming from the object storage.
Note: If you see the error below, you must set the search role in the node.
{
"error": {
"root_cause": [],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": []
},
"status": 503
}Known limitations at this stage
The searchable snapshots feature has several known limitations that users should be aware of when working with it.
Firstly, when accessing data from a remote repository, the search queries are expected to have higher latencies, due to slower access speeds, compared to local disk reads.
Secondly, the feature discards data immediately after readings, which means that subsequent searches for the same data will require the data to be downloaded again. To address this limitation, a disk-based cache for frequently accessed data will be implemented in the future.
Thirdly, it’s important to note that many remote objects store charge on a per-request basis for retrieval, so users should carefully monitor any costs incurred when using this feature.
Finally, searching remote data can potentially affect the performance of other queries running on the same node. Therefore, it’s recommended that users provision dedicated nodes with the search role for performance-critical applications.
Conclusion
Searchable snapshots is an experimental feature that allows users to search snapshots in remote repositories without having to download all index data to disks beforehand. This feature is part of OpenSearch’s Storage Roadmap, which aims to fully integrate external object storage systems like AWS S3 or GCS with search clusters, making long-term data searchable at a reasonable cost.
By following the steps outlined, users can create a searchable snapshot index with their OpenSearch cluster. While the feature has known limitations, such as higher latencies, immediate data discarding, and potential performance impact on other queries running on the same node, these will be addressed in future updates. Overall, the searchable snapshots feature offers a cost-effective, valuable solution for users who need to search remote data, minimizing OpenSearch cluster storage costs.